Écoute, posture et langues : la géographie acoustique du langage
Adapté de :
- A. Tomatis, Nous sommes tous nés polyglottes (édition italienne : Siamo tutti nati poliglotti), Edizioni Ibis, Como-Pavia, 2003.
- A. Tomatis, L'oreille et la vie, Edizioni Xenia, Como-Pavia, 2017.
- C. Campo, L'orecchio e i suoni fonti di energia, Edizioni Riza, Milano, 1993.
- C. Campo, Introduzione al metodo Tomatis, Università degli Studi di Ferrara, 2002.
- C. Campo, Il metodo Tomatis, Edizioni Xenia, Como-Pavia, 2020.
Écouter est un processus qui engage globalement notre organisme, caractérisant aussi de manière spécifique la posture : cela explique les liens psychologiques existant entre verticalité, équilibre et oreille. Mais il engage aussi, d'une certaine manière, la différenciation ethno-linguistique, en ancrant le langage dans l'environnement spécifique où il est parlé.
Pour qui connaît les études de Tomatis, l'affirmation selon laquelle verticalité et langage vont de pair chez l'homme est évidente. Pour clarifier cet aspect, il vaudra la peine d'ouvrir une parenthèse, en évoquant l'évolution phylogénétique de l'oreille à partir des espèces animales inférieures pour remonter peu à peu jusqu'à l'homme. La partie la plus profonde et la plus complexe de l'oreille, on le sait, est l'oreille interne. C'est un appareillage composé d'un centre qui contrôle l'équilibre — le vestibule — et de la cochlée, instrument d'analyse des sons et de recharge énergétique. C'est une sorte de coquille pleine de liquides et tapissée de cellules sensorielles. On peut en observer une ébauche très primitive chez l'hydroméduse, organisme très simple chez lequel on note un nerf latéral. Ce nerf présente huit centres qui sont autant de centrales énergétiques fonctionnant sous l'action du courant d'eau. Au cours de l'évolution de l'espèce, ce système, tout en restant fondamentalement le même, se perfectionne et s'enrichit d'un appareillage d'orientation. Chez certains poissons, à ce nerf latéral s'ajoute le tube latéral. Il s'agit d'un tube qui part de l'œil et qui entoure le poisson. Il se trouve sur les deux côtés de l'animal. Il est plein d'eau, étant muni d'ouvertures qui lui permettent de communiquer avec l'environnement extérieur. Ce tube fonctionne comme générateur d'énergie distribuée sous forme d'impulsions nerveuses, permettant ainsi au poisson de se mouvoir. Le tube latéral est ponctué d'ouvertures et s'accompagne d'un nerf appelé nerf latéral.
Pour fonctionner comme générateur d'énergie, ce tube latéral plein d'eau est tapissé de cellules sensorielles, appelées également cellules ciliées. Ce sont des cellules munies de cils disposés en petites touffes. L'eau qui passe dans le tube fait vibrer les cils à des fréquences très élevées. Les stimulations ainsi obtenues sont alors transmises au nerf latéral, qui les convertit en impulsions nerveuses.
Ce même tube latéral répond également à une seconde fonction. Si l'agitation des cils génère une énergie nerveuse, l'angle que ces cils forment avec la surface du tube varie selon les déplacements du poisson. Les mouvements de ces cils permettent ainsi au poisson de connaître la nature de ses déplacements et les forces du courant. Par exemple, il sent s'il descend ou s'il remonte vers la surface.
Au long de la chaîne de l'évolution, et déjà chez certains poissons, la ligne latérale se contracte et se referme pour devenir la vésicule otolithique. Le premier avantage qui en découle est que, en supprimant toute la longueur de la colonne d'eau, on élimine également le facteur d'inertie qu'elle représentait.
De la même manière que la ligne latérale, la vésicule otolithique fonctionne exactement comme l'antique tube latéral, avec des cellules ciliées immergées dans un milieu liquide. Comme la ligne latérale, la vésicule otolithique est sensible aux variations des déplacements des liquides désormais enfermés à l'intérieur. Pour augmenter cette sensibilité, elle est dotée d'une petite masse calcaire — une sorte de petit caillou — et chaque fois que l'animal tourne la tête, cette masse calcaire change de position et fait bouger les liquides qui l'entourent, générant ainsi de l'énergie et mesurant en quelque sorte ses déplacements.
La vie aquatique ne posait en pratique aucun problème de pesanteur ; mais à partir du moment où l'animal sort de l'eau pour vivre immergé dans l'air, il lui faut rendre son appareillage plus complexe afin de répondre à des besoins énergétiques majeurs et de contrôler désormais toujours mieux sa verticalité. À en juger par le parcours suivi par l'évolution, il semble que la posture verticale constitue pour le moment le stade le plus économique du point de vue de la dépense d'énergie vitale, et le plus rentable en termes de production énergétique. Chez le serpent, la vésicule otolithique se complexifie et se scinde en un saccule, qui a pour tâche de contrôler la verticalité, et un utricule qui assure l'horizontalité de l'animal. À l'utricule s'ajoute une ébauche de canaux semi-circulaires dont le rôle sera de contrôler les mouvements rotatifs. Bien que l'appareillage devienne plus complexe, sa fonction demeure essentiellement la même : générer de l'énergie et contrôler les mouvements.
Les matériaux utilisés n'ont pas changé : ce sont des cellules ciliées qui se meuvent dans un liquide. Lorsque apparaît, chez certains animaux, une partie nouvelle appelée lagena, on peut observer que certains de ces animaux relèvent sensiblement la tête. La lagena est développée au maximum chez les oiseaux, chez lesquels se trouve une ébauche d'oreille moyenne.
À la lagena succédera la cochlée, dont la présence détermine la verticalité. Elle est aussi l'instrument spécifique d'analyse des sons.
Évolution phylogénétique de l'oreille, de l'hydroméduse à l'homme.
Ce sont ces différents éléments qui forment chez l'homme le labyrinthe, c'est-à-dire l'oreille interne. C'est un générateur d'énergie qui permet en même temps de contrôler tous les mouvements du corps. Naturellement, l'oreille seule ne servirait à rien. Elle est enfermée dans une coque qui l'a modelée — le labyrinthe osseux — d'où émergent des nerfs partant de l'utricule, du saccule, de chacun des canaux semi-circulaires, pour constituer ce qu'on appelle le nerf vestibulaire, qui présente à un certain point un ganglion et se prolonge jusqu'à former les noyaux vestibulaires. Ceux-ci sont au nombre de quatre et fonctionnent exactement comme un cerveau primitif. Grâce aux nerfs qui partent des noyaux vestibulaires, sont atteints tous les muscles du corps, sans aucune exception.
Chaque fois que l'on est obligé d'adopter une posture ou une position d'équilibre quelconque, grâce à l'intervention des deux labyrinthes, une information est envoyée aux muscles à cette fin. Chaque muscle renvoie l'information pour avertir de sa position et de son état. Cette information revient à un relais intermédiaire qui se trouve dans le cervelet, relié au vestibule par les noyaux vestibulaires. Tous les mouvements musculaires passent ainsi par le labyrinthe.
Refermons cette parenthèse phylogénétique et anatomo-physiologique et, à la lumière de ce qui vient d'être dit, montrons le lien entre langage et posture. Pour utiliser au mieux les milliers de cellules ciliées de l'oreille interne, vestibule et cochlée doivent être orientés dans l'espace de telle manière que l'utricule se trouve en position horizontale et le saccule en position verticale ; c'est cette position qui donne le plus grand nombre de stimulations au niveau des cellules. C'est dans cette position que se produit la plus grande stimulation cérébrale. Et c'est la tête qui, en se positionnant correctement, place le labyrinthe selon ces axes — et la bonne posture de la tête dépend d'une bonne distribution des forces tensionnelles qui maintiennent le corps en verticale. Cette verticalité, à son tour, est mise en œuvre au moyen du circuit vestibule-cervelet-système musculaire.
Une oreille qui parvient à bien écouter — et surtout les sons aigus — favorise donc, à travers la cybernétique vestibulaire, une bonne verticalité. Le langage, qui s'accroche à la capacité très fine, acquise par l'oreille humaine, d'analyser les petites différences tonales correspondant aux divers sons contenus dans la langue, requiert une bonne écoute et une bonne verticalité.
Si l'on cherche en effet à parler à quatre pattes, et si l'on poursuit longtemps le discours dans cette position insolite, commence à se faire sentir un malaise qui n'est aucunement lié à l'inconfort apparent de la situation, mais à la difficulté de se mettre à l'écoute. Pour Tomatis, en effet, tendre l'oreille, c'est aussi tendre tout le corps à l'écoute — et pour cela il est nécessaire d'offrir à l'information les parties les plus sensibles de la personne. La partie antérieure de l'épithélium cutané est la plus riche en fibres sensorielles capables de capter, dans une certaine mesure, les sensations correspondant aux pressions. Ce réseau sensoriel parvient également à transmettre les informations au système squelettique, ajoutant ainsi une transmission osseuse aux stimulations informationnelles. Dès lors, l'écoute s'améliore et transforme l'attitude posturale, tandis que cette dernière permet à son tour à l'écoute de se perfectionner, grâce au message qui commence à parvenir de manière plus fidèle. Les actions, réactions et contre-réactions cochléaires et corporelles détiennent dans leur mécanisme les clés les plus importantes de la verticalité. Celles-ci évoluent en parallèle avec le langage, qui n'est rien d'autre, pour Tomatis, que la traduction biologique de l'acte d'écouter. En effet, tout laisse entrevoir qu'existe d'abord un dialogue sourd dans les bas-fonds de la structure linguistique, suivi d'un langage familier fait de conditionnements répondant à des nécessités immédiates ; vient ensuite la langualité socioculturelle qui devrait être l'affirmation de la fonction de l'audition, et permet dans une certaine mesure d'accéder à la compréhension de l'enseignement, dont elle est le vecteur. Enfin, à un dernier stade, apparaît le langage réflexif produit par une écoute profonde, ouvrant un dialogue avec la pensée elle-même, jusqu'à l'obtention d'une sécrétion verbalisée qui n'est rien d'autre que la pensée dans sa substance — ou le « logos incarné », pour paraphraser Tomatis.
Langage et image corporelle
La corrélation intime entre l'oreille et l'image corporelle globale passe par leur point de jonction : le langage. Celui-ci est fruit de l'écoute et exige, pour être contrôlé, affirmé, conduit jusque dans ses plus petites modulations, que l'oreille soit ouverte — et qu'elle le soit jusqu'à l'écoute. Ce qui n'est pas peu, car celle-ci introduit le champ conscient dans une dimension réelle.
Afin d'organiser ce dispositif particulièrement délicat, l'oreille guide — pour ne pas dire impose — tout un montage corporel au niveau de sa représentation mentale, reflet de l'image corticale. Ainsi, la personne qui parvient à acquérir un langage idéalement exprimé — et c'est déjà beaucoup d'y accéder — finit par s'installer dans une attitude posturale répondant à une attitude idéale, que peut atteindre celui qui parle en suivant des normes jugées excellentes. Le phénomène est encore plus net chez les chanteurs et les acteurs qui se trouvent, pour des raisons professionnelles, mis en condition de devoir acquérir une émission parfaite des sons qu'ils doivent fortement contrôler. Les postures sont très révélatrices et permettent de comprendre, dans ce cas, la nécessité d'une tenue scénique bien définie en vue de la réalisation d'un acte qui exige une perfection d'exécution. Avec l'Oreille Électronique, l'appareil inventé par Tomatis pour rééduquer l'écoute, il est aisé de voir des changements posturaux en fonction des modifications auditives introduites. Effectivement, en imposant grâce à des bascules électroniques une audition riche en fréquences aiguës, on observe, au moment où la phonation s'anime, une corrélation posturale notable. On note surtout un redressement de la colonne vertébrale et une ouverture sensible de la cage thoracique ; à cela s'ajoute la recherche d'une meilleure rectitude dorsale grâce à une rotation du bassin par antéversion de la partie pubienne. En même temps, le visage se détend et se mobilise harmonieusement, sans tension, tandis que la voix s'illumine. Il est très difficile d'observer, par exemple en classe, un enfant qui suive attentivement les leçons en étant avachi sur sa chaise. Et il serait compliqué de mettre en marche le mécanisme de l'écoute en maintenant une telle posture. De plus, celui qui parle a la sensation d'être écouté lorsque son interlocuteur se tient dans une posture droite, et non lorsqu'il apparaît affaissé sur lui-même.
Tomatis propose un exercice pour comprendre ce qu'est la posture d'écoute. Il l'appelle training audiogène. On peut l'adopter en partant d'une position assise sur un tabouret réglé en hauteur de manière à avoir les genoux légèrement plus bas que le bassin, pour favoriser le bon positionnement de ce dernier. Les yeux clos, la tête cherche son point d'équilibre pour favoriser une perception optimale des tons aigus présents dans l'environnement. Il s'agira ensuite de mobiliser adéquatement la musculature de l'oreille moyenne. On commence en imaginant que tout le cuir chevelu vienne se rassembler dans la partie supérieure de la tête — le vertex — qui correspond au point de tonsure des moines. Cela fait, les rides qui sillonnent horizontalement le front commencent à disparaître. Si tout va bien, on a une sensation nette à la racine des cheveux, avec une perception de fraîcheur dans cette partie du crâne.
Cette opération réussie, on imaginera maintenant d'élargir le front, comme si la peau voulait toucher les parois de la pièce dans laquelle nous nous trouvons. Aussitôt après, ramenons cette peau pour qu'elle se rassemble au même point où nous avons fait un chignon avec le cuir chevelu, en serrant bien, pour que la peau se tende. À ce point, si les opérations ont été correctement exécutées et que la tête a été maintenue dans la position indiquée au départ, les rides verticales du front, s'il y en a, commencent à s'aplanir, et certaines modifications vasomotrices commencent à se produire : le visage rougit et se réchauffe, puis perd de la couleur, tandis que la respiration devient plus large et plus profonde, plus détendue : elle tend réellement à se débloquer, à devenir ce qu'elle devrait normalement être.
Les paupières, jusqu'à ce moment volontairement abaissées, se ferment sous l'effet de leur poids, accompagnées d'un tremblement dans leur partie externe. À ce point, en imaginant toujours, prenons la peau du visage située sous le front et étirons-la jusqu'à ce qu'elle touche elle aussi les parois de la pièce. Cela fait, on ramène également cette partie de peau pour la rassembler dans le petit chignon situé au sommet de la tête. À cela viendront s'ajouter les deux oreilles qui viendront se placer sur le sommet du crâne.
L'action au niveau de la peau sera évidente. On aura la sensation qu'une fine couche de caoutchouc a été appliquée sur le visage, tant l'action se ressent dans les muscles faciaux. C'est comme un « lifting physiologique » qui agit sur eux. De plus, dans le même temps, la lèvre supérieure est laissée à reposer sur la lèvre inférieure comme sur un chapiteau. S'établit ainsi un équilibre entre les muscles orbiculaires des lèvres et ceux qui agissent sur leurs commissures, tandis que la mâchoire inférieure maintient le contact avec la supérieure sans contractions. À ce point, le visage commence à prendre une expression très détendue et reposée, comme libéré des marques que les préoccupations laissent sur la peau. Parvenu à ce stade — très agréable à vrai dire, et tel que celui qui l'éprouve voudrait le maintenir pour toujours —, en conservant la quiétude faciale, on cherche à percevoir l'environnement. À ce point, on s'aperçoit que quelque chose change. Les bruits commencent à se purifier, prennent un timbre plus clair. Les sons graves s'atténuent tandis qu'augmente la composante d'aigus présente en eux. Tout semble devenir plus lumineux et vif.
Si l'on cherche à écouter sa propre voix dans ces conditions, on a la sensation de la percevoir pour la première fois — plus timbrée et riche en harmoniques. On a en outre la sensation que c'est l'oreille droite qui dirige l'écoute et qu'elle entraîne l'oreille gauche en un point localisé au sommet de la tête, précisément là où nous avons rassemblé le petit chignon. Physiologiquement, cela s'appelle le point de fusion.
L'idéal serait que l'on parvienne, dès ce moment, à percevoir sa propre voix comme si elle était ancrée en ce point. Cette manière de percevoir les sons et sa propre voix a un corrélat, si l'on peut dire, psychologique : la possibilité de mieux objectiver ses rapports à soi-même et aux autres.
C'est cette posture d'écoute qu'adoptent les bons chanteurs de manière inconsciente lors de l'allumage de leur voix. C'est la posture de l'écoute libre, délibérée, sans entraves, où la personne peut s'écouter et écouter sans interférences provenant des profondeurs « limbiques » de la conscience.
Le son sculpte le corps
Le langage oriente donc la posture du sujet vers une certaine direction. Meilleure est la qualité du langage — c'est-à-dire de l'écoute, le premier dépendant de la seconde —, meilleure est l'attitude posturale. Nous pouvons imaginer le corps soumis à l'œuvre modelante du son, en pensant qu'il est entouré de stimuli et d'impulsions qui excitent continuellement tous ses points. La somme de ces pressions finit par composer une image intégrée du corps. Il est très facile de ressentir cela en s'immergeant dans une étendue d'eau agitée. Au toucher des vagues, on perçoit mieux la limite du corps.
Naturellement, il existe des zones privilégiées, plus sensiblement touchées par le son et le langage : le visage, la face antérieure du thorax et du ventre, la face dorsale de la main droite entre pouce et index, la partie interne des membres inférieurs (surtout au niveau du genou), la plante des pieds. Ce sont les zones de la surface corporelle à plus forte densité de fibres nerveuses spécialisées dans la perception des stimuli pressifs. Il devient ainsi plus clair que la verticalité est nécessaire afin d'offrir la plus grande surface possible aux stimuli sonores, si l'on veut développer le langage. Selon Tomatis, la posture verticale ne serait toutefois pas la meilleure dans l'absolu à cette fin ; il en existerait une autre d'origine orientale, plus précisément l'asana du lotus dans la discipline du Yoga, qui (coïncidence ?) permet une meilleure exposition des zones corporelles décrites précédemment aux stimuli acoustiques.
Il est intéressant de noter que l'image corporelle propre peut être imposée à l'autre, plus ou moins consciemment. À ce sujet, Tomatis raconte une expérience vécue en Afrique du Sud, avec un sujet bègue. Une personne extrêmement brillante, atteinte d'un fort bégaiement accompagné de mouvements désordonnés. En peu de temps, durant la consultation à laquelle assistaient d'autres personnes, tous se mouvaient comme lui, avec les mêmes gestes. Le plus étonné était l'interprète, qui était le plus engagé dans le langage de ce sujet. Son image du corps était si forte que, durant la consultation, il l'avait imposée à tous. Cela arrive lorsque la personnalité est forte. De la même manière, un bon chanteur nous euphorise : en peu de temps, c'est comme si nous-mêmes chantions ; la respiration s'amplifie, le visage se détend. En présence de chanteurs médiocres, on en vient à souffrir, en ce qu'on tend à faire comme eux : on pousse sur le larynx en serrant la gorge. Selon ces perspectives, un dialogue advient lorsque deux personnes se mettent en vibration l'une avec l'autre. Selon Tomatis, ce que nous désirons originellement transmettre n'est ni des manières, ni des sons, mais des sensations profondément ressenties, profondément vécues en nous par nos neurones sensoriels. Ce que nous désirons communiquer, ce sont les impressions tactiles que la parole fait courir sur notre clavier sensoriel. Sans le savoir, nous transmettons les mêmes accords à notre interlocuteur, qui, inconsciemment, fait fonctionner son propre clavier à l'image du nôtre — de sorte que nous entrerons en résonance.
Une vérification expérimentale de la compatibilité des images corporelles peut être faite en imposant à deux sujets des courbes auditives identiques et en les lançant dans une discussion épineuse : très difficilement entreront-ils en désaccord. Ensuite, on inverse les courbes et l'on entreprend un dialogue très banal : il est très facile que, dans l'espace de quelques minutes, les deux personnes soient en train de se disputer. Cela montre à quel point le mental est influencé par le corps, et combien celui-ci, à son tour, modifie le langage par lequel il est sculpté. L'interaction esprit-corps est donc réciproque. Laquelle des deux parties est à l'origine du processus d'interaction, il est difficile de le dire.
Posture ethno-linguistique
Un autre facteur très important qui influence l'image corporelle est ce que Tomatis appelle l'impédance acoustique du milieu. On appelle ainsi l'ensemble des résistances minimales que l'environnement offre à la propagation du son. Tout milieu à travers lequel le son voyage offre une certaine résistance au son lui-même, favorisant ou non son passage, accentuant ou diminuant son intensité sur certaines fréquences. Or, l'air est le milieu principal par lequel le son est transmis. La voix, le son d'un instrument, un bruit, avant de parvenir à l'oreille du récepteur, traverse une couche d'air plus ou moins grande selon la distance entre émetteur et récepteur. L'air, cependant, n'est pas le même partout dans le monde, ni même à l'intérieur d'un même pays. De nombreux facteurs géographiques, climatiques, environnementaux influent sur la consistance de l'air, de manière différente, en différents points de la surface terrestre. Tomatis a parcouru le monde longtemps avec un appareillage très simple consistant en un microphone relié à un enregistreur et un haut-parleur diffusant des sons identiques à une distance déterminée. En analysant les mêmes sons émis par le haut-parleur dans diverses zones géographiques — grâce à des analyseurs panoramiques décomposant les sons dans leurs différentes composantes fréquentielles —, il apparaissait évident que le même son, en fonction du lieu géographique où il était enregistré, était plus riche de certaines fréquences que d'autres. Il pouvait être, en un certain lieu, plus riche en fréquences aiguës ; en un autre, plus riche en fréquences graves, etc. Dans l'espace entre le haut-parleur et le microphone, la seule chose à changer d'un lieu à l'autre était l'air. Pour le confirmer, Tomatis a analysé un vaste échantillon de voix de personnes des mêmes lieux où il avait enregistré le son émis par le haut-parleur. La correspondance des fréquences était stupéfiante ; on pouvait déterminer des zones linguistiques qui n'avaient rien de commun avec les frontières socio-géographiques. On a pu construire une géographie acoustique assez détaillée de diverses zones géographiques. Immergée dans un bain acoustique particulier, l'oreille se met à privilégier les fréquences les mieux perçues dans cette zone, et par voie de conséquence influence la phonation. Certes, les facteurs héréditaires, culturels et sociologiques sont à prendre en considération ; l'influence des critères acoustiques demeure cependant considérable.
Il y a quelques siècles, l'émigrant anglais s'est installé sur le continent américain où l'air vibre davantage à 1 500 hertz — fréquence qu'il peut entendre, mais qui lui provoque des sensations différentes de celles auxquelles il est habitué.
Peu à peu, sa perception a changé, et avec elle tout son système profond de réponses auditives et de contre-réactions neuronales. Il a acquis une autre posture, une autre attitude, spécifique de la nouvelle ethnie. Il a modifié son comportement, adopté une approche psychologique inhabituelle. Ces nouvelles conditions ont obligé le corps à s'adapter au nouvel univers acoustique. La tension du tympan n'est plus la même. Le système nerveux, pour être en accord avec la cochlée, est contraint de modifier son fonctionnement. À son tour, une partie de l'oreille moyenne — en particulier le muscle de l'étrier — doit changer sa modalité opératoire. Étant celui-ci sous le contrôle du nerf facial, les muscles du visage sont soumis à une gymnastique inhabituelle. Le muscle du marteau, qui est innervé par le même nerf que celui qui commande la mandibule, choisit lui aussi des positions adaptées à cette nouvelle opérativité. Les traits subissent en conséquence un lent, mais inexorable, lifting physiologique.
Les paramètres des langues
À la suite des analyses ci-dessus mentionnées et d'autres études sur le langage, Tomatis identifie quatre paramètres qui permettent de mieux comprendre le fantastique monde des langues vivantes. Ces quatre critères, que nous pouvons définir comme les caractéristiques d'une langue, sont : la bande passante, la courbe d'enveloppe à l'intérieur de la bande passante, le temps de latence et le temps de préparation de l'oreille moyenne, ou précession.
La bande passante
L'audition humaine se développe sur un spectre sonore allant des sons graves aux sons aigus, distribués de 16 hertz jusqu'à environ 16 000-20 000 hertz. Toutefois, dans ce large spectre de 11 octaves, les fréquences ne sont pas toutes perçues de la même manière. Il existe dans chaque langue des zones préférentielles, ou bandes passantes, à l'intérieur desquelles les sons sont perçus avec une plus grande netteté. La cause en est l'impédance acoustique des lieux et des environnements. Nous savons que l'on parle avec un timbre tout à fait différent selon que l'on se trouve dans une pièce réverbérante ou dans une chambre sourde.
« Sur le continent américain, dit Tomatis, les habitants ne nasalisent pas pour le plaisir. Les anciens émigrants anglais ou hollandais ne s'étaient certainement pas épris des langues amérindiennes, caractérisées par cette particularité phonétique. Ce n'est pas la langue américaine qui fait nasaliser. C'est "l'air du lieu", plus riche acoustiquement entre 1 000 et 2 000 hertz, qui oblige l'oreille à adopter la bande passante spécifique de la nasalisation. » Parallèlement, la langue française, qui utilise préférentiellement les fréquences entre 1 000 et 2 000 hertz, avec une zone de sensibilité maximale à 1 500 Hz, présente elle aussi la nasalisation dans sa phonétique.
La courbe d'enveloppe
À travers l'étude de la chaîne parlée au moyen d'analyseurs panoramiques et de sonographes — appareils capables de décomposer les sons comme le prisme parvient à décomposer la lumière dans les couleurs qui la composent —, il a été possible de visualiser les diverses fréquences en respectant quantitativement les valeurs relatives de chacune d'elles, et de repérer les diverses parties d'une phrase, en fréquence, en intensité et en durée. Sur les phonogrammes et sonogrammes ainsi obtenus, il a été possible de trouver les courbes d'enveloppe des valeurs moyennes des fréquences rencontrées au cours de l'analyse des phrases recueillies dans un même groupe ethnique.
Quelques exemples avec les principales langues européennes peuvent éclairer ce concept. Les diagrammes de ces courbes ont été appelés par Tomatis ethnogrammes et montrent, pour chaque groupe ethno-linguistique, les zones fréquentielles de plus grande sensibilité auditive. En abscisse sont indiquées les fréquences, en ordonnée les intensités.
Le temps de latence
Ouvrir une porte, saisir quelque chose, se gratter… présuppose un état prévisionnel, un temps de préparation, dit de latence. Lorsqu'on décide de regarder quelque chose, on prépare la vision, on met l'objet au point. Avant de raccorder les images des deux yeux, avant de mettre parfaitement au point, un temps de latence s'est établi.
Dans le cas de l'oreille, il s'agit du temps nécessaire pour se mettre à l'écoute. D'un bout à l'autre du globe terrestre, nous ne tendons pas l'oreille de la même manière. Ce phénomène, appelé par Tomatis temps de latence ou retard, varie selon les zones géographiques mais aussi selon l'âge. De nombreux enfants irritent leurs parents lorsqu'ils les obligent à répéter deux ou trois fois la même phrase. Leur oreille n'est pas encore parvenue au rythme de reconnaissance linguistique des adultes. Ils ont un temps de latence plus long que le nôtre. Les publicitaires connaissent bien ce phénomène. Dans leurs plans publicitaires, ils tiennent compte du nombre d'affiches collées sur les murs ou de la fréquence des spots diffusés à la télévision. Ils savent que leur impact diffère selon ces paramètres.
Lorsqu'on commence à parler et que l'on se prépare à s'écouter — chacun de nous étant le premier auditeur de son propre discours —, on introduit entre nous et notre langage une dimension, un préparatif parfaitement mesurable et qui joue sur le flux verbal et l'accentuation. Le temps de latence est significatif dans les chansons, dans les chants folkloriques, dans les manières de raconter les histoires. Ces produits de la tradition, en effet, nous apportent le rythme prélinguistique de la langue, sur lequel vient s'accrocher la sémantique. Tomatis dit que, pour la plupart de nos contemporains, le fait que l'écoute dépende d'une posture du corps semble une chose incompréhensible. On oublie cependant que l'oreille ne se contente pas de déchiffrer les sons comme le ferait la tête de lecture d'un magnétophone. Elle dispose d'un appareillage — le vestibule — qui induit le sujet à mettre son corps dans une position déterminée pour pouvoir répondre. Le vestibule est le siège de l'équilibre, mais de lui dépendent également le tonus des muscles, leur force relative, et surtout la conscience de l'image corporelle. Un temps de latence long, comme le temps slave, renforce l'image corporelle. Il permet en outre une analyse plus précise des sons, grâce à l'allongement du temps de mise en œuvre.
Ce n'est peut-être pas un hasard si beaucoup de spécialistes de phonétique sont d'origine slave.
Tomatis est arrivé à mesurer les temps de latence de nombreuses langues, et a pu constater combien cet élément est important comme critère de différenciation entre elles.
Aujourd'hui, nous savons par exemple qu'Anglais et Espagnols partagent la primauté de la rapidité linguistique, à 5 millisecondes. Cette performance est aisée pour les Espagnols, qui parlent très près des sons fondamentaux laryngés. Pour les Anglais, elle devient un tour de force, à cause de la bande passante aiguë qui les contraint à parler avec la pointe de la langue, à plus de quinze centimètres du larynx.
Le temps de précession
Le dernier paramètre à prendre en considération dans les recherches psycholinguistiques de Tomatis concerne un processus d'intégration audio-corporelle appelé temps de précession. Il s'agit en effet de la précession qui manifeste la conduction osseuse par rapport à la conduction aérienne, et correspond au temps nécessaire à l'oreille moyenne pour synchroniser la tension tympanique au son déjà perçu par la voie osseuse. Il varie d'une langue à l'autre, et de lui dépend la manière différente de réagir aux divers registres linguistiques, en faisant adopter au corps des postures différentes pour mieux se synchroniser avec eux.
La géographie acoustique
La langue française
Dans le cas du français, on peut noter que les zones fréquentielles de plus grand usage se situent l'une entre 100 et 300 hertz — donc dans les graves —, l'autre vers les aigus, entre 1 000 et 2 000 Hz, avec un point de plus grande sensibilité à 1 500 Hz. La différence d'intensité sonore entre ces deux zones est d'environ 20 décibels. Le pic à 1 500 Hz, avec la chute relative vers les aigus, explique l'apparition de la nasalisation dans cette langue. Cette bande passante, unie à un temps de latence de 50 millisecondes, fait du français une langue hyper-vocalique avec un faible accent tonique. Pour donner un exemple : une personne française prononce le mot « Bonjour » à la française. Nous entendrons un glissement linéaire fait, dans une première partie, d'un petit « b » et d'un grand « ON », et dans une seconde partie d'un petit « j » et d'un grand « OUR ». Au contraire, si c'est un locuteur natif américain qui prononce le même mot, nous aurons une prononciation hyper-consonantique typique de l'américain : un Bon-Jour avec un grand « B », un petit « on », un grand « J » et un petit « our ». Le français, en outre, utilise la zone de fréquences typique du langage. Cela pourrait peut-être expliquer, en partie, l'importance que revêt le langage en lui-même dans la culture française.
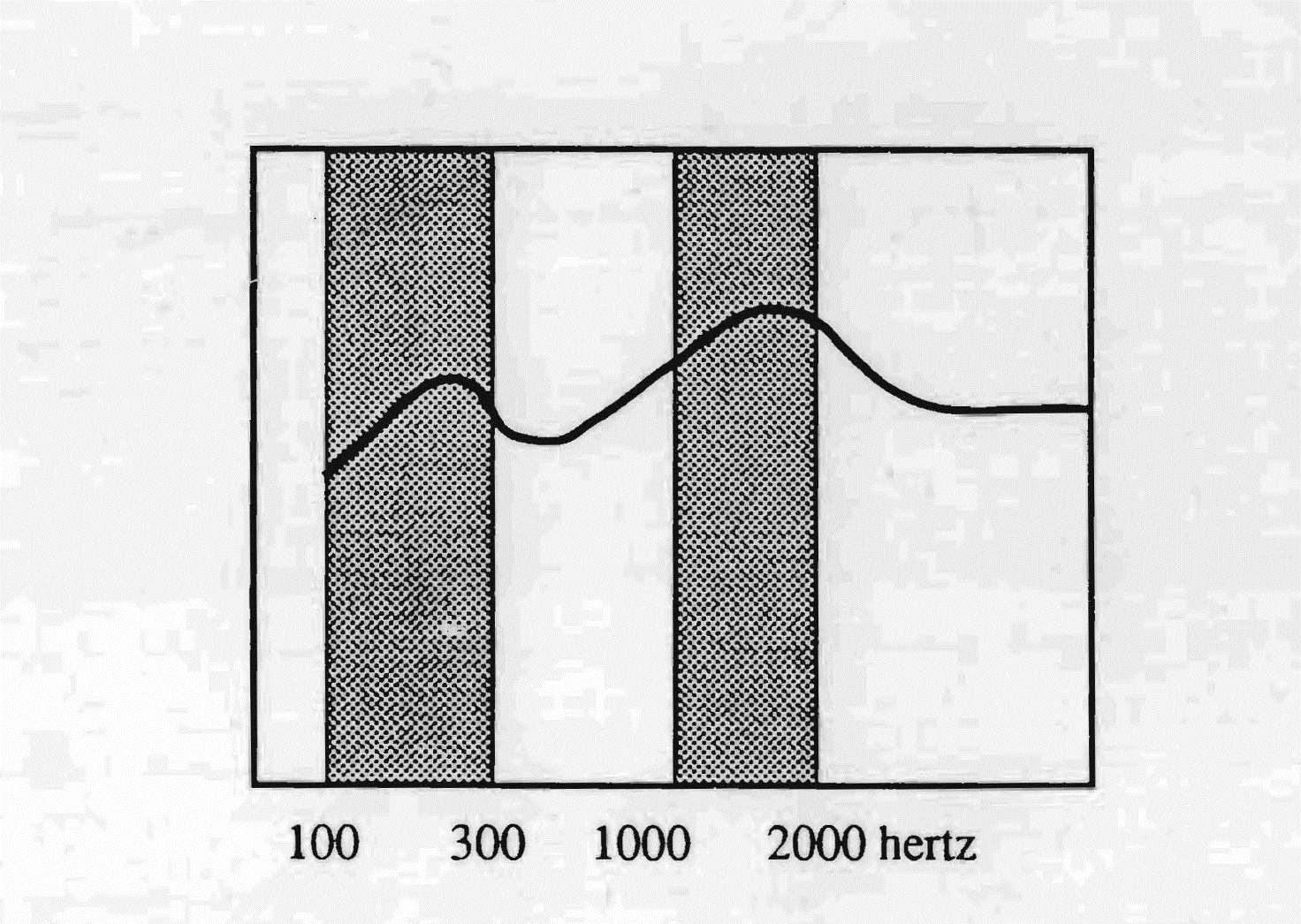
La langue française utilise les fréquences allant de 100 à 300 Hz et de 1 000 à 2 000 Hz.
La langue anglaise
La caractéristique essentielle du type d'audition à l'anglaise est représentée par la grande sensibilité aux sons aigus et un temps de latence très rapide, qui influent — le second sur le temps d'émission syllabique, le premier sur l'image corporelle concentrée sur la partie haute du corps.
Il s'agit naturellement de l'anglais parlé en Angleterre. À partir de 2 000 Hz, la courbe trace une progression de l'ordre de 6 décibels par octave qui se prolonge jusqu'à 12 000 hertz et même au-delà — ce qui confère à ce type d'audition une courbe de réponse qui rappelle celle des circuits d'amplification haute fidélité. La conséquence en est la richesse des sifflantes dans cette langue.
Dans la coulée verbale de type anglais, l'attraction vers les aigus de tout le schéma vocal explique, par contre-réaction auditive, la diphtongation systématique des voyelles. Celles-ci, bien qu'elles existent dans le spectre initial, glissent du son fondamental vers la bande de fréquence située au-delà des 2 000 Hz. En effet, la bande passante aiguë perçue par l'oreille anglaise impose, par contre-réaction audio-vocale, une structure telle que le son fondamental — qui se trouve dans les graves en raison des possibilités limitées du larynx (300 hertz) — ne peut être maintenu dans l'émission initiale, n'étant pas sélectionné par l'oreille. Par conséquent, on assiste de fait à un glissement vers les aigus qui produit la diphtongation. Il est intéressant de remarquer que la distance qui existe entre le son fondamental — initialement le même dans toutes les langues, et toujours grave — et la bande passante d'une langue explique la différence, plus ou moins grande, entre la reproduction écrite d'une langue et sa prononciation. Cette modification est d'autant plus importante que la différence est grande. Par exemple l'espagnol, fixé principalement sur les sons graves, s'écrit pratiquement comme il se prononce, tandis que l'anglais présente un maximum de distorsion entre la langue parlée et sa reproduction écrite. En confrontant la bande auditive anglaise à celle française, on note que l'une utilise des fréquences non sélectionnées par l'autre oreille, et vice versa. On sait bien que pour l'oreille française il est difficile de percevoir l'anglais et vice versa. La langue américaine, qui utilise une bande passante plus basse que l'anglais britannique, avec un point de sensibilité maximale à 1 500 hertz, est mieux perçue par l'oreille française que l'anglais d'Oxford.
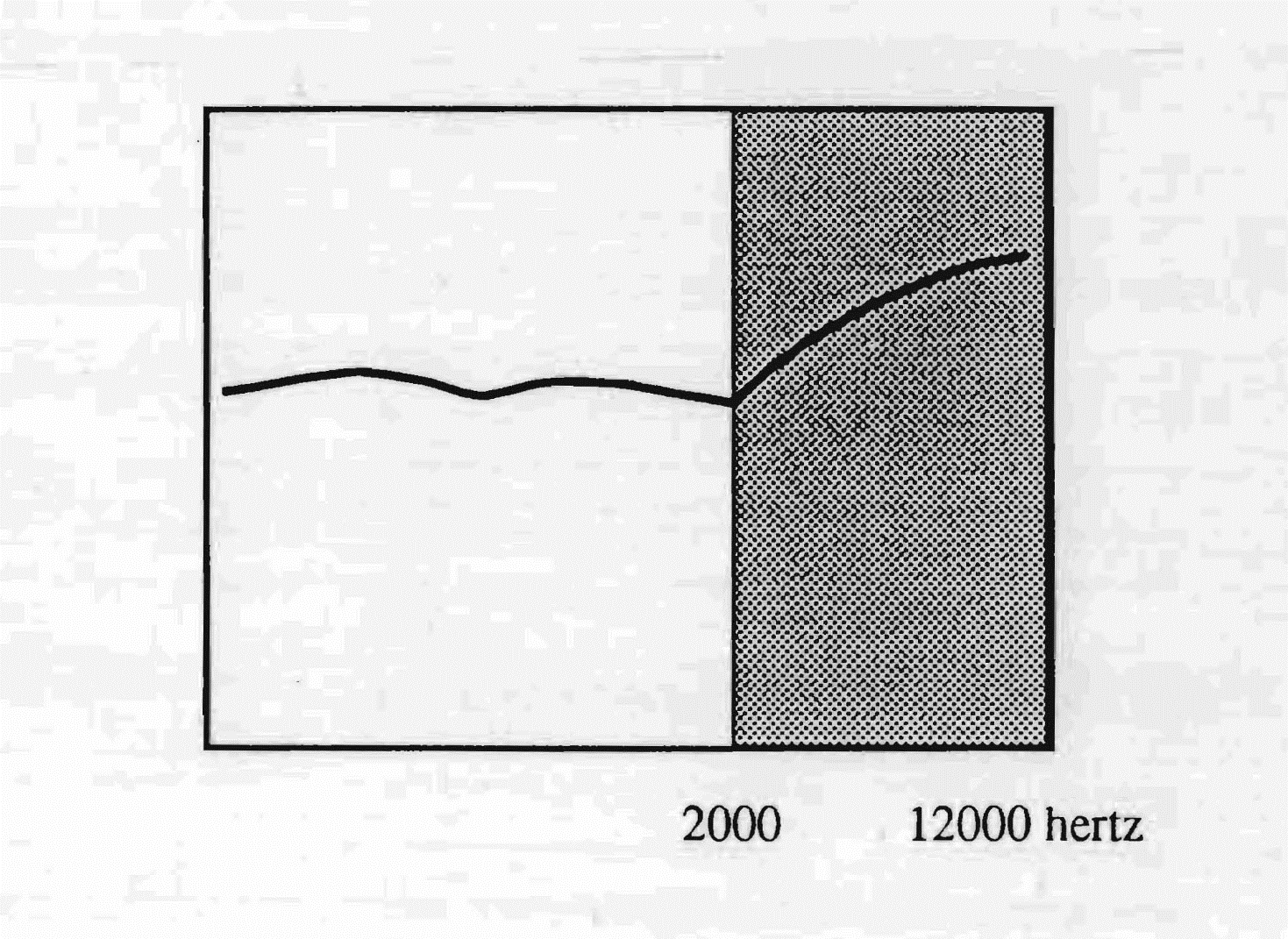
La langue anglaise utilise les fréquences allant de 2 000 à 12 000 Hz, avec une plus grande sensibilité dans les fréquences très aiguës.
La langue allemande
La bande passante de la langue allemande part des graves et s'étend jusqu'à 3 000 hertz. La sensibilité est plus accentuée entre 250 et 2 000 hertz, avec un pic de plus grande perméabilité autour de 800 hertz. La largeur de cette bande passante permet d'intégrer aisément les phonèmes appartenant à d'autres langues, à condition qu'ils s'inscrivent dans son territoire fréquentiel.
À cette large bande passante s'ajoute une caractéristique très importante de l'oreille allemande : un temps de latence relativement long. Cela implique une forte poussée du larynx et un engagement corporel notable durant la phonation, nécessaire pour soutenir la poussée laryngée — caractéristiques de ce groupe linguistique.
Il est important de noter que pour écouter et parler une langue déterminée, il faut se mettre dans l'attitude qu'elle impose. Ce sont les paramètres acoustiques — bande passante, courbe d'enveloppe, latence et précession — qui imposent la posture et l'attitude motrice, grâce au dialogue constant entre cochlée et vestibule. Par exemple, pour écouter et parler l'allemand, il faut se tenir particulièrement droit, avoir le thorax bien ouvert et être bien planté sur ses jambes. Attitude corporelle qui a peu à voir avec celle d'un Anglais ou d'un Espagnol.
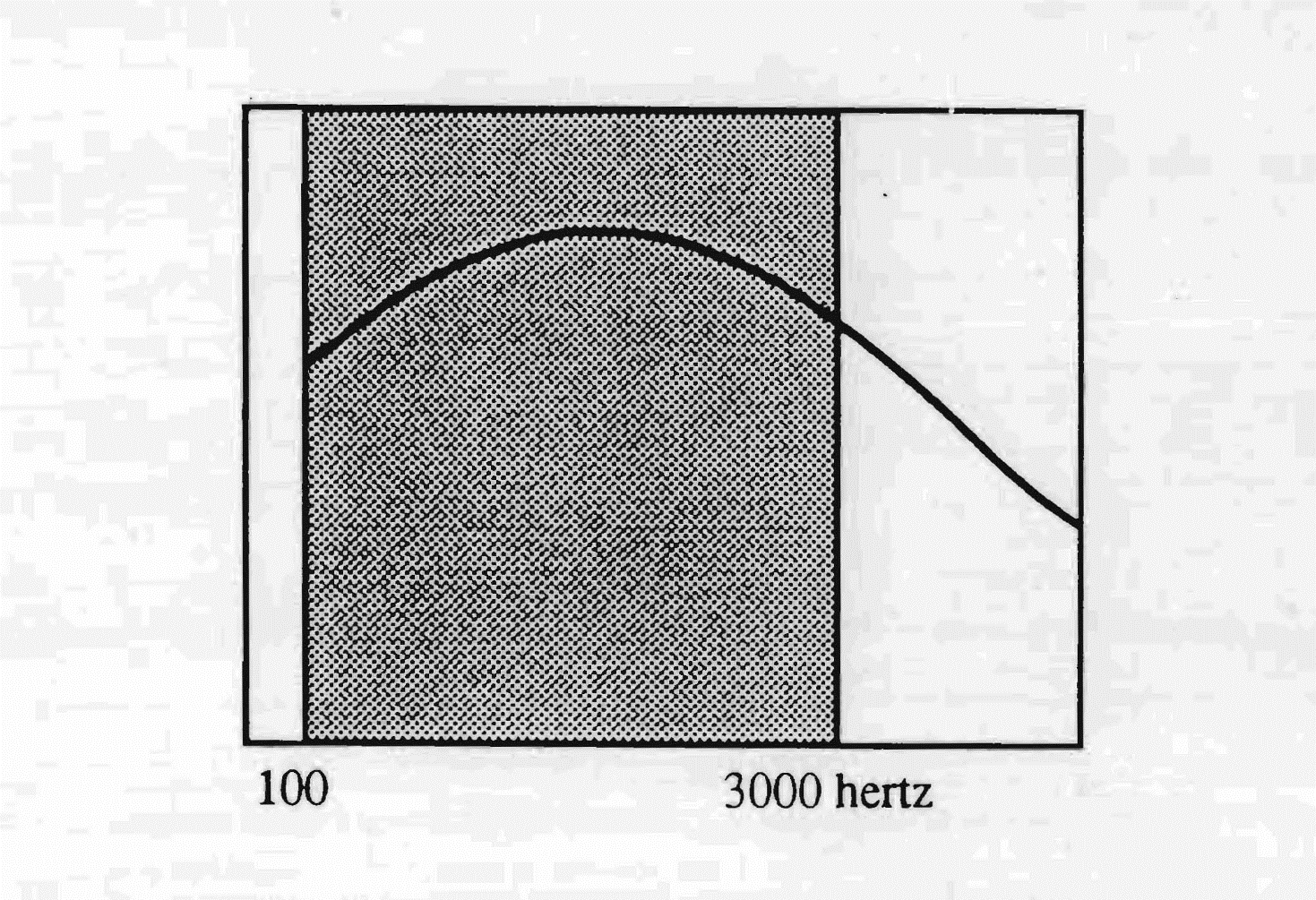
La langue allemande utilise les fréquences allant de 100 à 3 000 Hz, avec une plus grande sensibilité autour de 750 Hz.
La langue espagnole
Caractéristique de l'oreille de type espagnol est une grande sensibilité aux sons graves sur une bande qui va jusqu'à 500 hertz, et un niveau d'intensité moins élevé dans une autre zone allant de 1 500 à 2 500 hertz, avec une sensibilité très réduite dans les aigus.
Le pic à 250 hertz introduit, dans la réaction audio-vocale, la jota, tandis que l'absence de perméabilité dans les aigus au-delà de 2 500 hertz explique la lourdeur des sifflantes espagnoles : le glissement par exemple du « f » en « h » aspirée. Il est évident, à la lecture du graphique, que l'Espagnol moyen rencontre une difficulté à intégrer les langues étrangères. L'usage prépondérant des fréquences basses dans la langue castillane favorise une image corporelle qui investit beaucoup le bassin et les jambes.
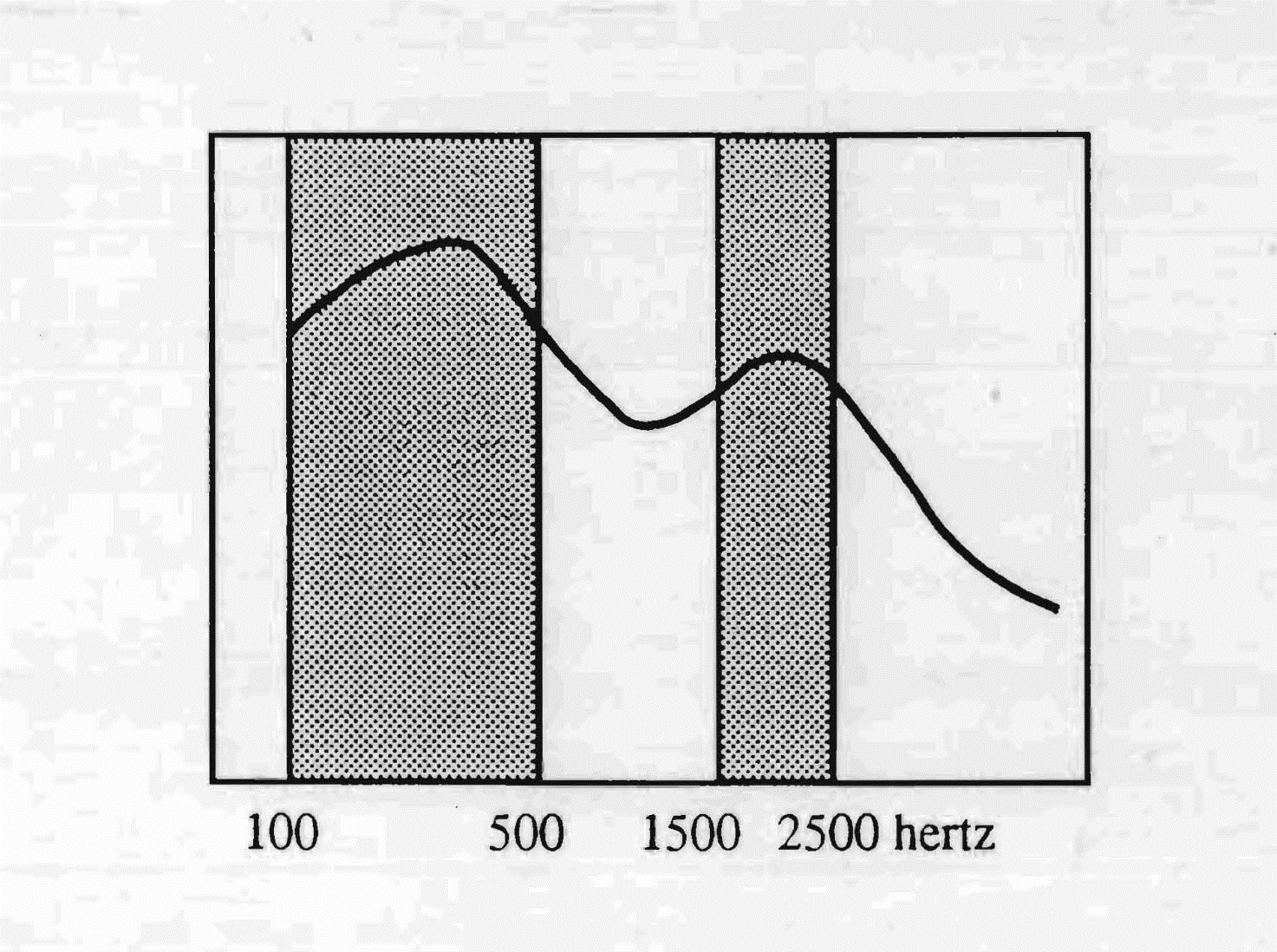
La bande passante de l'espagnol castillan va de 100 à 500 Hz et de 1 500 à 2 500 Hz. L'oreille de type espagnol est plus sensible aux sons graves, où la voix est plus forte. La faible sensibilité aux aigus explique l'absence de sifflantes dans cette langue.
La langue arabe
La langue arabe, en revanche, est caractérisée par une bande passante très proche de celle de l'espagnol castillan, et un temps de latence de type allemand. De là l'absence de sifflantes comme dans la langue espagnole, et une forte poussée laryngée typique des locuteurs de l'allemand.
Les langues slaves
Les Russes et les Slaves en général disposent d'une ouverture très étendue du diaphragme auditif, allant des sons graves jusqu'aux plus aigus, avec une affinité plus marquée vers les tons graves. Cette richesse sélective, contrairement à celle des Français, permet une excellente perception des phonèmes des autres langues.
Le réflexe audio-postural du groupe linguistique de type slave se caractérise par la manière de se tenir bien planté au sol, par l'ampleur de la respiration, par sa façon d'émettre des sons larges et chauds — signe d'une forte intégration corporelle. Celle-ci dépend tant de la large bande passante que du temps de latence de la perception, assez long pour favoriser une forte prise en charge du son par le corps.
Il est intéressant de remarquer que chaque groupe ethno-linguistique a la posture de son langage, conséquence de sa manière d'écouter.
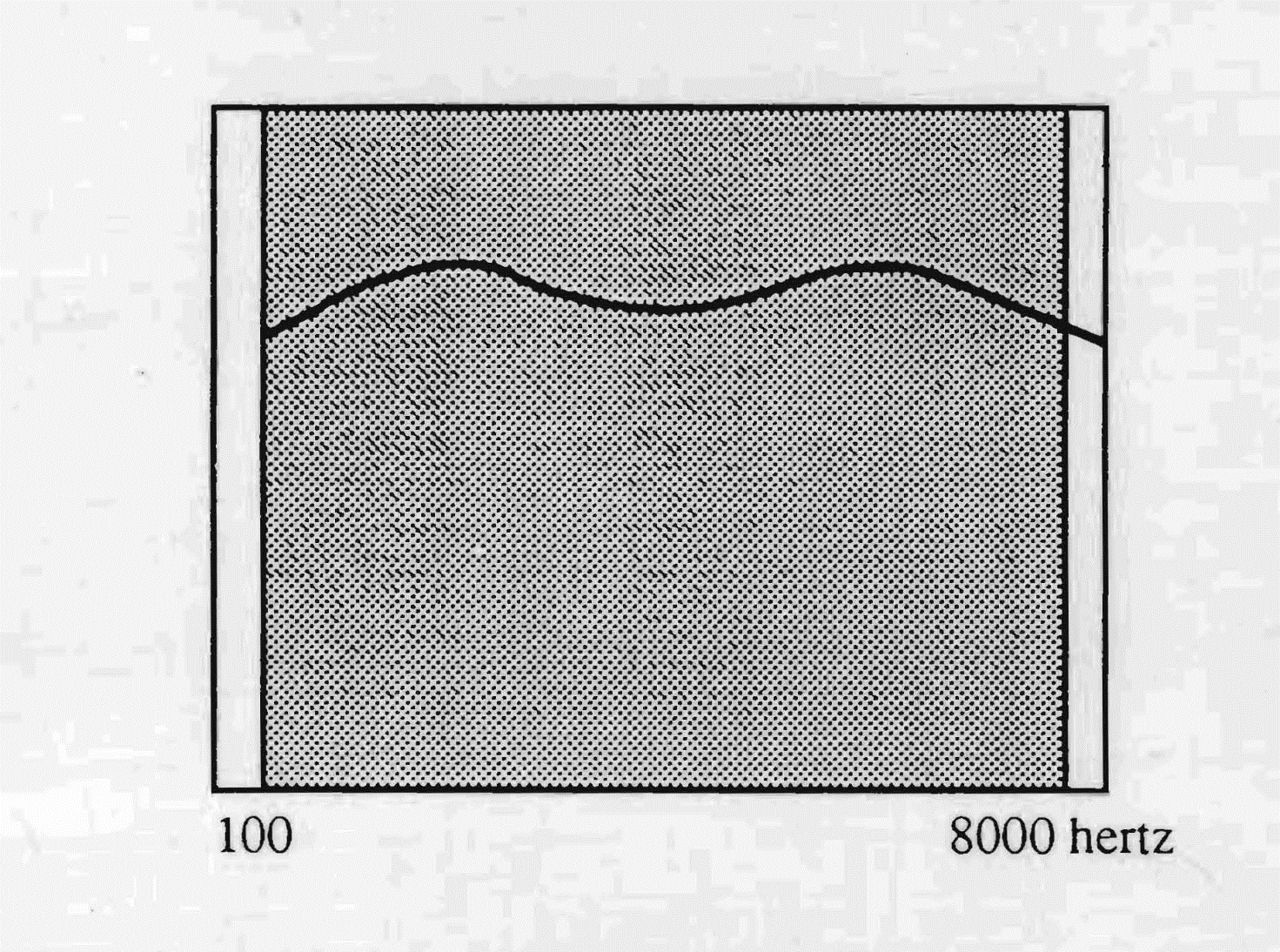
Les bandes passantes des langues slaves couvrent presque toutes les fréquences utilisées par l'oreille humaine. De là, la facilité de leurs locuteurs à apprendre aisément les autres langues.
La langue portugaise
La langue portugaise, celle parlée au Portugal, présente les caractéristiques des langues slaves (bande passante, retard et précession). Elle résonne comme un espagnol auto-contrôlé par une oreille de type slave. Expérimentalement, il est amusant de vérifier ce fait en faisant passer une phrase portugaise à travers des filtres dont la courbe de réponse est celle de l'oreille espagnole. Pour qui comprend l'espagnol, le portugais devient ainsi plus aisément compréhensible.
La langue italienne
La courbe d'enveloppe de la langue italienne, jointe à la zone fréquentielle particulière couverte par sa bande passante et aux temps de latence qui lui sont propres, indique une oreille très musicale.
La bande passante, sans être très étendue — de 2 000 à 4 000 Hz —, touche une zone fréquentielle très favorable au chant. En parlant de l'italien, on dit souvent que c'est une langue musicale. Ce n'est pas un hasard si le chant lyrique est né précisément ici. Entre 2 000 et 4 000 Hz, l'ossature présente la plus grande résonance, et le son osseux est celui qu'un chanteur lyrique émet quand il chante avec qualité.
C'est en effet le larynx qui, en vibrant contre les vertèbres cervicales, fait entrer en résonance toute la structure squelettique très sensible aux sons aigus, produisant le son typique de la manière de chanter à l'italienne. Le tout favorisé par la réaction audio-posturale liée à l'écoute de type italien.
La musicalité de l'écoute — et donc de la phonation — de type italien est favorisée également par l'ascendance de la courbe d'enveloppe, qui monte des graves vers les aigus avec une pente d'environ 6 décibels par octave jusqu'à 3 000-4 000 hertz, pour fléchir ensuite légèrement vers les extrêmes aigus.
Pour Tomatis, ce type de courbe est très proche de ce qu'il appelle l'écoute musicale idéale. Les temps de latence (75 millisecondes) et de préparation (150 millisecondes) typiques de la langue italienne influencent le temps d'émission syllabique et favorisent la prononciation des consonnes et des voyelles en juxtaposition, donnant à la langue son rythme exquisément musical. La « luminosité » des sons de la langue provient de sa bande passante située dans la zone de la mélodie.
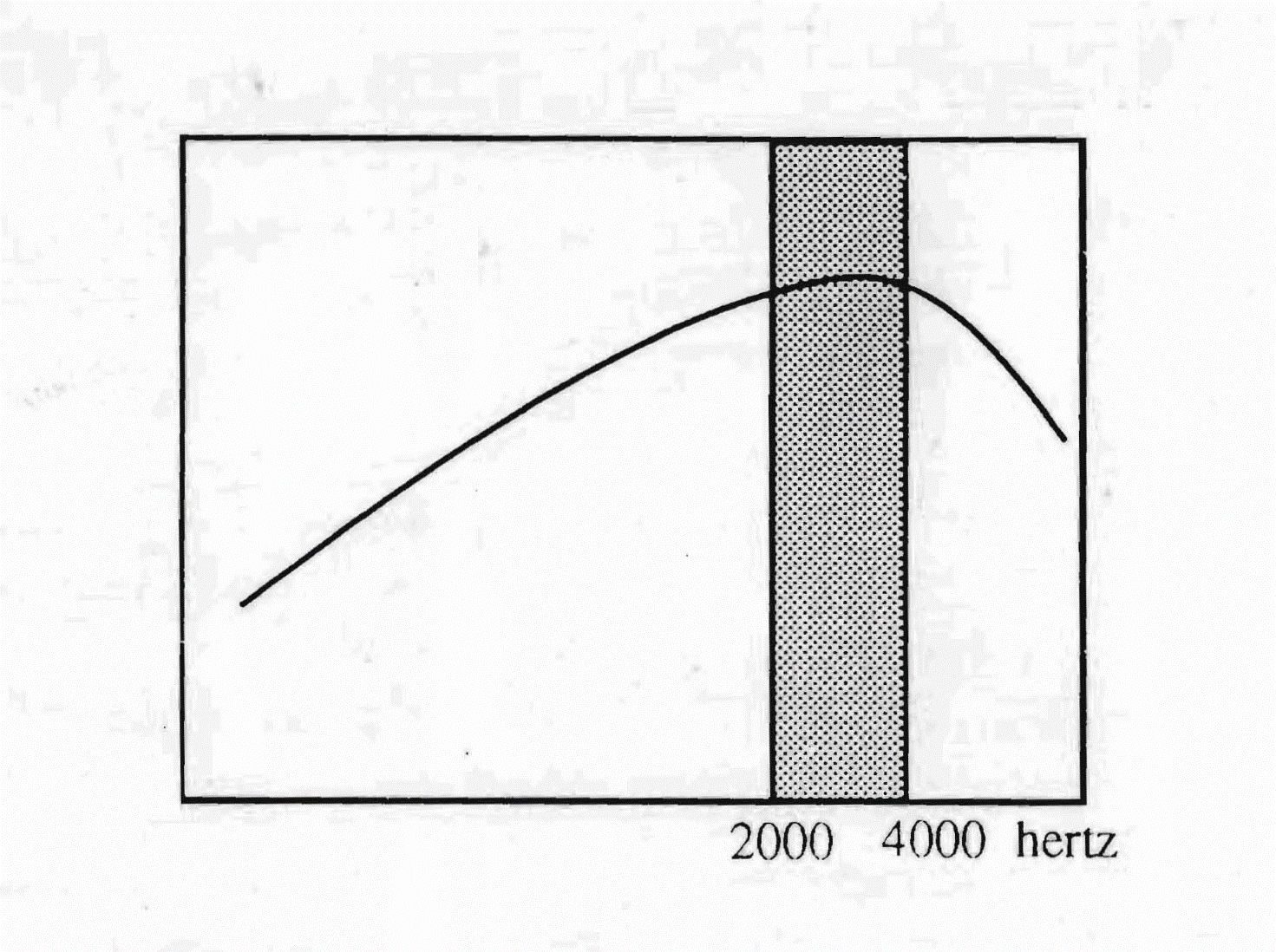
La bande passante de la langue italienne couvre une plage de fréquences allant de 2 000 à 4 000 Hz. L'évolution ascendante de la courbe d'enveloppe — des graves jusqu'à 3 000 hertz — et l'inflexion légère qui suit dans les aigus donnent une écoute de type musical.
Texte original par Concetto Campo, publié sur tomatis.it. Traduction française.